NoSQL Reference Architectures
Mongo Database Architecture:

Sharding
This is a method of horizontally partitioning data in a database. This concept is similar to Partitioning explained earlier. Each individual partition is referred to as a 'Shard'. MongoDB distributes the read and write workload across the shards and provides horizontal scalability.
Mongo DB will distribute data into different shards based on a shard key. A shard key is a field which should exist in every document of a collection.
For instance, in a system which stores student information across US, State could be a Shard Key. MongoDB provides two components to allow data distribution:
- Router (known as Mongos).
- Config Server
The config Server would track and store the metadata. It also stores information on which shard key is stored in which shard.
The Clients should never connect to individual shards, but always should go through Mongos. The Mongos router would cache the metadata information and would route the query request to the appropriate shard. If a shard key is not included in the query request, Mongos would broadcast the query to all the shards.
Redis Architecture:
Redis is an In-memory, Key value based database. Redis stores all the data in memory (RAM), so it provides faster access to data. But we need to keep the memory limitation in mind. One of the use cases where Redis could be used is in ‘session persistence’. Another use case is to use Redis as a distributed cache (to cache frequently used data).
Redis supports persistence of data to the disk. Redis could be configured to store data to the disk at regular intervals.
Redis also supports Replication (Master/Slave) and Clustering (Sharding) modes of configuration.
Cassandra Architecture:
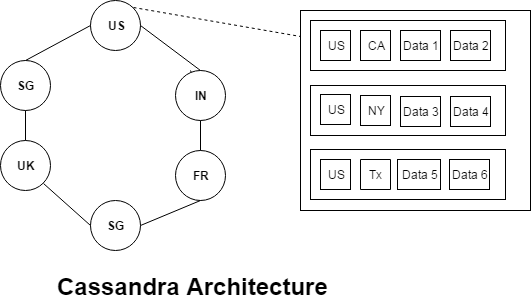
Cassandra has a distributed architecture, where data is distributed among multiple nodes and is also replicated to handle fail overs. Cassandra has a peer to peer distributed system, where in, the clients can fire a query by connecting to any node in the cluster. That node would be responsible to coordinate with other nodes and return the results. (Note that there is no Master node in this setup). So every node would be aware of the metadata and configuration (nodes communicate with each other using a protocol known as ‘Gossip Protocol’). A Cassandra cluster could be generally visualized as a ring consisting of multiple nodes where data is distributed consistently across all the nodes.
Cassandra is a row oriented database. Every table has a Partition key (or a combination of keys) and a Clustering key (or a combination of keys).
Partition Key decides which partition the data would go to. Clustering key decides which cluster in a given partition, the data resides and helps in sorting the data in a partition.
For instance, in the above diagram, let us say the country code is the partition key and state code is the clustering key. Each partition would get data depending on the hash of the country code. So one partition would get US, another partition would get IN etc. Within each partition, the data would be sorted using clustering key which is the state code.
So when a row is inserted into a table, a hash function of the partition key is calculated and this hash function would decide which node would get that partition. Similarly, while performing a read operation, based on the partition key provided in the read operation, the specific node which contains that partition would be queried.
For this reason, it is very important to have a data model built around querying patterns in Cassandra. If the partition key changes often, then using Cassandra is not a good fit. Also, the queries must have a partition key to avoid querying all nodes and avoid scanning all partitions.
Cassandra is generally a good fit for heavy writes since it performs very well on writes.